MariaDBで全文検索を試してみる
前回、MySQLでMeCabプラグインを導入して全文検索を設定しました。
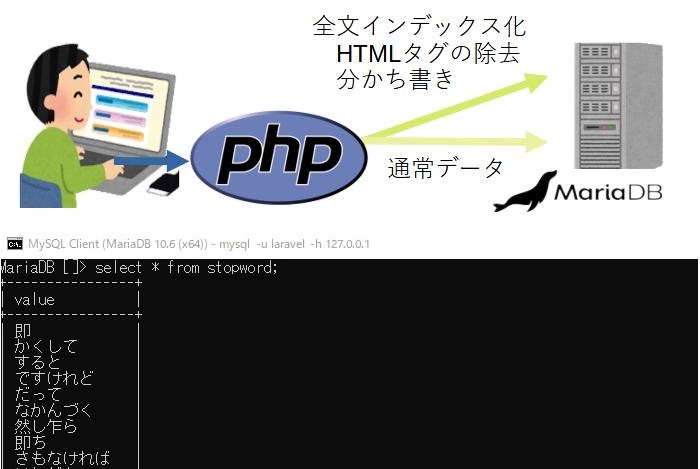
前回の記事の作業をする中で、筆者が常用しているMariaDBでも全文検索を実現するプラグインがあったり、単語毎に分割するMeCabパーサーや、文字数ごとに分割するNグラムパーサーが使えないだけで、単語を自分で文書を“分かち書き”(空白区切りの単語への分割)すればMariaDBでも日本語の全文検索ができそうなこともわかりました。そこでこの記事ではMariaDBに日本語の全文検索を実際に設定してみます。
例示する環境としてはWordPressのようにな環境を想定しています。MariaDBのカラムにHTMLのタグを含んだ本文を保存して、ブラウザのPHP経由でそれを読み書きするものです。全文検索用にカラムは本文とは別に設けて、本文の“分かち書き”は、PHP側で行います。
テーブルの作成
MariaDBでデータを格納するテーブルを作成します。これはMySQLに設定した際と変わりはありません。FULTEXT INDEXでインデックスを格納するカラムを指定します。
CREATE TABLE html_doc(
id INT AUTO_INCREMENT PRIMARY KEY,
html TEXT,
index_words TEXT,
FULLTEXT INDEX(index_words)
)CHARSET=utf8mb4;
分かち書き
前回は日本語を単語に分解するのにMeCabを利用しました。PHPでexec関数を使ってこれをそのまま利用呼び出してもいいのですが、PHPだけで完結するものがないか思い探していたらigo-PHPを見つけました。
ただこれは少しコードが大きいと思っていたところに、PHPではなかったのですがTinySegmenterというJavaScriptのライブラリを見つけました。ソースコードのサイズが25Kという小ささに魅かれて、これをPHPに変換して使ってみることにしました。
TinySegmenterをPHPに変換したコードのソースは、元のライブラリのライセンスを継承した形でGithubに公開していますので、よろしければご利用ください。
変換したコードをrequireした後、インスタンスを生成して、セグメントメソッドに分かち書きしたい文章の文字列を渡すと結果が配列となって返ります。
これを再度文字列に戻して全文インデックスを設定したMariaDBの行に格納します、impolode関数で一行にまとめてしまうと空白を返している時に空白がつながるので、foreachを使ってチェックしています。この辺の処理は好みの問題かもしれません。
sample.php
require_once(__DIR__.'/TinySegmenterPHP.php');
// インスタンスの生成
$segmenter = new TinySegmenterPHP();
$segment = $segmenter->segment("分かち書きしたい文章を入力してください。");
$result="";
foreach($segment as $v) {
if (trim($v)=="") continue;
$result .= $v." ";
}
HTMLタグの除去
TinySegmenterを使えば簡単に“分かち書き”ができますが、文章がHTMLタグで装飾されている場合はそのままだとノイズが多くなります。
そのため事前に本文からHTMLタグを除去します。これにはPHPに用意されているsprip_tags関数が利用できます。
strip_tagsを利用する場合にも注意点があります。まず、scriptやstyleタグで囲まれたデータがあった場合単純にタグを取り除くだけなので、JavaScriptのコードやCSSが残ってしまうということです。
そのため、strip_tagsを実行する前に、scriptやstyleタグで囲まれた部分を除去します。複数のブロックに分かれていることがあるので開始タグから終了タグの最短一致を正規表現で除去します。
scriptやstyleタグの内側に同じタグががあると意図した除去ができませんが、その点は考慮しないことにします。
scriptタグは属性に、type=moduleやsrc等が入ることがあるので、開始のタグの>は記述しません。
sample.php
...
// scriptタグと中身の除去
$data = mb_ereg_replace('<script.*?</script>','',$data);
// styleタグと中身の除去
$data = mb_ereg_replace('<style.*?</style>','',$data);
...つぎに、<br>タグで改行がされている際、改行前に句読点がなかった場合は、前の行の末尾と次の行の先頭がくっついてしまいこれも“分かち書き”判定のノイズになることです。
たとえば、「パイン<br>アップル」というHTMLがあった場合、brを単純に除去すると「パインアップル」と一語になってしまいます。
なので、brタグはを半角スペースに置き換えるようにします。
sample.php
...
// brタグを半角スペースに変換
$data = mb_ereg_replace('<br ?/?>',' ',$data);
...改行と不要な文字の除去
HTMLタグを取り除いた後、さらにノイズになりそうな文字を除去します。
まず改行です。改行は改行コードという単なる文字なので、それを構成する、¥rと¥を半角スペースに変換します。単純に消去しないのは先のbrタグにも説明があったように行の前後がくっつかないようにするためです。同様に句読点や.や,も単語の分割や、文の終わりを示している場合があるので半角スペースにします。
※・「」といった記号や全角スペース、文字エンティティ(&など)も同様に処理します。
記号は限りがないのと、文脈によっては必要だったりすることもあるので、運用しながらのチューニングが必要になると思います。
// 除去したい記号
$targetString='[ 。、・【】「」<>〇●◎〇◆◇□■▲▽▲△→⇒←↑↓☆★※*“”]';
$data = mb_ereg_replace($targetString," ",$data);
ここまでの処理で。のあとにbrタグが来ていたりすると空白がつながることがあります。まとめたいのなら次のようにします。
// 二文字以上のスペースをひとつにまとめる
$data = mb_ereg_replace(" +"," ",$data);
ここでまとめてもTinySegmenterを通すと半角スペースが出現することがあるので、空白の連続が気になる人はTinySegmenterの結果から空白を除去する作業も必要です。
ストップワード
全文検索においてはストップワードというものがあります。検索対象としては意味をなさない単語を指定してインデックスの対象外とするリストです。
デフォルトのストップワードのリストは次のようにすると出力されますが、これらは英語環境を対象にしています。
MariaDB[]>SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD;
a
about
an
are
...日本語を対象に考えた場合、助詞、接続詞、連体詞、副詞あたりがストップワードの対象になると思います。WindowsでMeCabをインストールすると付属しているipadicは品詞別に分かれた.csvファイルになっているのでそれを利用してストップワードのリストを作ります。たとえば助詞は、Postp.csvファイルに記述されています。
Postp.csv
にゃ,326,326,6598,助詞,特殊,*,*,*,*,にゃ,ニャ,ニャ ばかし,350,350,4865,助詞,副助詞,*,*,*,*,ばかし,バカシ,バカシ てん,273,273,8007,助詞,終助詞,*,*,*,*,てん,テン,テン より,155,155,5542,助詞,格助詞,一般,*,*,*,より,ヨリ,ヨリ すら,258,258,5294,助詞,係助詞,*,*,*,*,すら,スラ,スラ ...
ストップワード用のテーブルを自作します。これはinformation_schemaの中にテーブルを作成したり、INNODB_FT_DEFAULT_STOPWORDに値の挿入ができないためです。
テーブル構造は元のINNODB_FT_DEFAULT_STOPWORDと同じものにします。valueというvarchar(18)のカラムをひとつだけ持つテーブルです。
MariaDB[]>CREATE TABLE my_stopword SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD WHERE 1=2;
先ほど作成したテーブルにデータを挿入します。
最後に設定ファイルにストップワードテーブルを指定する記述をします。
合わせて、innodb_ft_min_token_sizeでインデックスする単語の最小文字数を指定します。英語では1字や2字で終わる単語の大半がインデックスの必要がない言葉ですが、日本語では1字や2字で意味をなす言葉が少なくないので1を指定します。
[mysqld]
innodb_ft_min_token_size=1
innodb_ft_server_stopword_table = 'データベース名/ストップワードテーブル名'
前回のMySQLの記事にも書きましたが、目的のテーブルに全文インデックスを付与する際にinnodb_ft_server_stopword_tableの値がセットされていないと、INNODB_FT_DEFAULT_STOPWORDの値を参照し続ける点に注意してください。修正したい場合は、ALTER TABLEコマンドで全文インデックスをつけ直すことで可能です。
英語では文章自体が“分かち書き”できているので、ストップワードをデータベースに設定するのは理にかなっていますが。“分かち書き”処理を別途行う今回の場合は、ストップワードに含めるべき単語をTinySegmenterで分割したあとPHP側で除去する方法もあると思います。また、今回は利用しませんでしたがPHPでMeCabを呼び出せば品詞の判定もできるので、品詞単位で除去するという方法もあると思います。