MeCabで漢字のフリガナを取得
MSエクセルだと環境によってですがPHONETIC関数やVBAのApplication.GetPhonetic関数で、漢字を含む文字列の「読み」をカタカナ変換することができます。 これをMSエクセルのない環境で処理したいと思って形態素解析器であるMeCabを使って実現しました。
形態素解析器
日本語のセンテンスを単語単位に分解するアプリを、形態素解析器と呼びます。オープンソースで使えるものの中で有名なものにMeCabがあります。Windows用のバイナリは辞書も付属していて手軽に利用できますのでこちらを使いたいと思います。
ライセンス形態は、GPLライセンス(ライセンスの詳細はこちらに記されています)となっています。
MeCabの他には、Sudachiや、JUMANがあります。
WindowsでのMeCabのインストールと基本的な使い方
最初にWindowsでのインストール方法から紹介します。WindowsMeCabのインストールは、先のサイトからWindows用のインストーラーをダウンロード、起動してウィーザードに従ってインストールします。
途中、利用する文字コードを聞いてくることがあります。特に意図がなければ「 Shift-JIS 」を選択します。

インストール後、デスクトップにMeCabへのショートカットができますので、これを起動するとMeCabのプロンプトが起動します。「 Shift-JIS 」で辞書を設定した場合は、ここに好きな文字を入れ、Enterキーを押すことで分かち書きができます。
Mecab
好きな文字を入れれます 好き 名詞,形容動詞語幹,*,*,*,*,好き,スキ,スキ な 助動詞,*,*,*,特殊・ダ,体言接続,だ,ナ,ナ 文字 名詞,一般,*,*,*,*,文字,モジ,モジ を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 入れ 動詞,自立,*,*,一段,未然形,入れる,イレ,イレ れ 動詞,接尾,*,*,一段,連用形,れる,レ,レ ます 助動詞,*,*,*,特殊・マス,基本形,ます,マス,マス EOS
プロンプトを立ち上げる他の方法には、 echo コマンドで mecabに渡す方法があります。
コマンドプロンプト
c:\users\user> echo 今日はいい天気です | "C:\Program Files (x86)\MeCab\bin\mecab" 今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー は 助詞,係助詞,*,*,*,*,は,ハ,ワ いい 形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ 天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス EOS
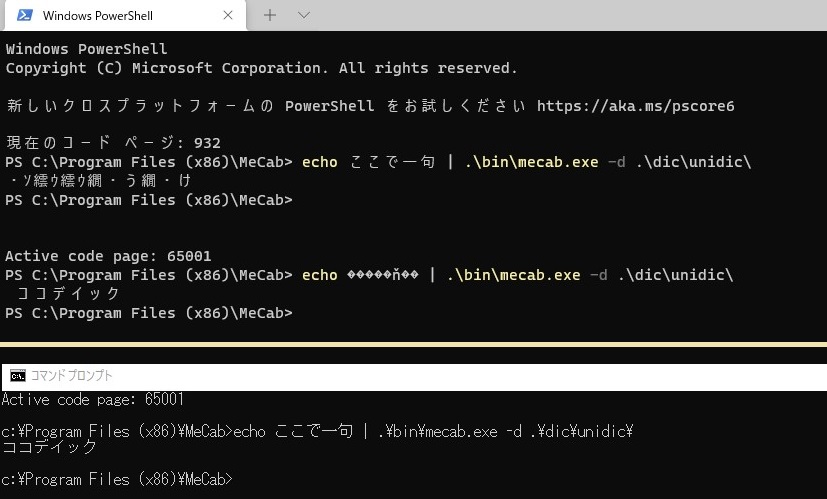
この方法は、先の設定で「 Shft-JIS 」を選択した時、コマンドプロンプトではうまくいきますが、PowerShellではうまくいきません。
PowerShell
PS> echo 今日はいい天気です | & "C:\Program Files (x86)\MeCab\bin\mecab" ????????? 名詞,サ変接続,*,*,*,*,* EOS
このパイプの後の&記号は文字列をコマンドとして明示するために設定しています。
これが文字化けするのはechoで渡される文字列が Shift-JIS ではないためにおきるようです。
パイプとして渡す文字列のエンコーディングを Shift-JIS にする方法は、筆者には見つけられませんでした。
代替処理として、パイプではなくMecabコマンドラインのパラメータとして、対象の文字列を格納したファイルを指定するといった方法があります。
「 c:\テスト.txt 」に Shift-JIS エンコーディングで「今日はいい天気です」という文字列が格納されているとします。
PowerShell
PS> & "C:\Program Files (x86)\MeCab\bin\mecab" c:\テスト.txt 今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー は 助詞,係助詞,*,*,*,*,は,ハ,ワ いい 形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ 天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス EOS
PowerShellでechoのパイプを使いたい
WindowsにバンドルされているPower Shell(5.1)系ではパイプを使う方法は見つけられませんでしたが、PowerShell Core(7~)においては内部の文字コードがUTF-8なので、先ほどの辞書のエンコーディングを UTF-8 にすれば、PowerShellのパイプを利用した変換でも期待する結果が得られます。
PowerShell Coreのインストーラーはリンク先より取得できます。マルチプラットフォーム化されて環境別にファイルが存在しますので、環境にあったものを選択してください。
PowerShell には内部で利用する文字コードの他、インプット時の文字コード、アウトプット時の文字コードの設定がありますので、利用時にはこれらもUTF-8 に合わせます。
PowerShell Ver7.4
# 入力文字コードをUTF-8に PS> [Console]::InputEncoding = [System.Text.Encoding]::UTF8 # 出力文字コードをUTF-8に PS> [Console]::OutputEncoding = New-Object System.Text.UTF8Encoding # 実行 echo 今日はいい天気です | & "C:\Program Files (x86)\MeCab\bin\mecab" 今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー は 助詞,係助詞,*,*,*,*,は,ハ,ワ いい 形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ 天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス EOS
MeCabの引数にファイルを指定する際は、ファイル内の文字列のエンコーディングも UTF-8 にしておく必要があります。
また、コマンドプロンプトで文字コードを UTF-8 にしたい場合は「 chcp 65001 」を指定します。そうすることで、PowerShell(7)同様に UTF-8 の辞書環境で利用可能です。
デスクトップにあるショートカットではそのままだと文字化けがおきますので、ショートカットをやめてbatファイル化して、chcp 65001 を実行してから立ち上げるようにします。
MeCabへのショートカット改.bat
chcp 65001 "C:\Program Files (x86)\MeCab\bin\mecab.exe"
PowerShellでもコマンドプロンプトでも、一度ウインドウが終了すると文字コード変更の効力がなくなりますので、変更は都度行ってください。
Debian(Linux)でのインストール
Debian(Linux)でインストールする場合は apt を利用すると簡単です。筆者の環境ではJUMAN用の辞書をMecab用にコンバートしたものが同時にインストールされました。文字コードを聞いてきませんが、OSのデフォルトエンコーディングが UTF-8 なので自動で UTF-8 の辞書が採用されるようです。
Debian
$ su - ... # apt update ... # apt install mecab ....
Debian(Linux)からMeCabを実行する際もWindowsと同じバリエーションがあります。
ショートカットはありませんが、mecab と打ち込むだけで mecab のプロンプトに移動します。このプロンプトを終了させるには、Ctrl + Cを押します。
echoを使った場合の出力例です。
$ echo 今日はいい天気です | mecab 今日 名詞,時相名詞,*,*,今日,きょう,代表表記:今日/きょう カテゴリ:時間 は 助詞,副助詞,*,*,は,は,連語 いい 動詞,*,子音動詞ワ行,基本連用形,いう,いい,連語 天気 名詞,普通名詞,*,*,天気,てんき,代表表記:天気/てんき カテゴリ:抽象物 です 判定詞,*,判定詞,デス列基本形,だ,です,* EOS
引き数にファイルパスを渡すことも、Windows同様に可能です。
Debian(Linux)においては、Windowsと比べて出力形式が変わっていますが、これは辞書とその設定ファイルによる影響です。
辞書の更新
MeCabは辞書を使うタイプの形態素解析器です。辞書だけを基準にで分かち書きを行うのではでなく「学習」という要素も加わりますが、辞書の内容により結果は変わります。
Windowsインストーラーの同梱版の辞書は、元々コンパクトサイズになっているのに加え、新しい言葉が入っていません。
新しい言葉に対応したり、多くの語彙を持つ辞書を使いたくなった場合は、自身で辞書を更新することができますが、別に提供されている辞書を利用することも可能です。今度はその方法を紹介します。
インストーラーにバンドルされているIPADICは更新が途絶えていますので、他にMeCabで利用可能な辞書のひとつであるUnidicを例にとって説明します。こちらは2023年の時点でもメンテナンスがされているようです。
MeCabと辞書はまったく別物です。そのため辞書(Unidic)には独自のライセンスが存在します。GPL v2.0他のマルチライセンスになっているようですが、詳細は先のリンク先から確認した上に適切に利用してください。
Unidic:「現代書き言葉」からファイルをダウンロードして展開します。ユースケースに応じて「話し言葉」をダウンロードしてもいいと思います。

ダウンロードして展開したフォルダの名前を「 unidic 」とします。辞書ファイルはどこにあっても対応可能な設計ですが、MeCabのプログラムフォルダ内の dic フォルダが辞書格納用のそれとなっていますので、その中に入れます。(C:\Program Files (x86)\MeCab\dic)
MeCabの設定ファイルの辞書の指定を変更します。windowsでは、MeCabのプログラムフォルダ内の etcフォルダ、Debian(Linux)で apt でインストールした場合は /etc/に、「 mecabrc 」というファイルがあり、これを適当なテキストエディタで編集します。
Windowsのプログラムフォルダにある場合は、そのままだとセキュリティの都合で編集できないので、一旦ファイルをユーザー領域に移動させてから、編集して元に戻すという手順を踏みます。
mecabrc
; ; Configuration file of MeCab ; ; $Id: mecabrc.in,v 1.3 2006/05/29 15:36:08 taku-ku Exp $; ; ; 辞書ファイルをipadicからunidicに変更します ; dicdir = $(rcpath)\..\dic\ipadic dicdir = $(rcpath)\..\dic\unidic ; userdic = /home/foo/bar/user.dic ; output-format-type = wakati ; input-buffer-size = 8192 ; node-format = %m\n ; bos-format = %S\n ; eos-format = EOS\n
デフォルト値が「 $(rcpath)\..\dic\... 」となっていますが、これは MeCab のプログラムフォルダ dicフォルダを指しているようなのでそのまま差し替えましたが、全体を絶対パスにする事もできます。
先ほどから文字コードの話をしていますが、文字コードは辞書に対する設定となります。MeCab付属のIPADICでは、MeCabのインストーラーが選択した文字コードに辞書データをコンバートしてくれますが、Unidicの文字コードは UTF-8となっており、これを変換するのは手間ですのでそのまま UTF-8 で使います。ここでは、PowerShell(7.4)を使いますが、先ほどもあったようにPowerShellの新しいバージョンがインストールされていなければ、コマンドプロンプトで「 chcp 65001 」を実行した後に行ってください(その場合は&は不要です)。
PowerShell Ver7.4
PS> [Console]::InputEncoding = [System.Text.Encoding]::UTF8 PS> [Console]::OutputEncoding = New-Object System.Text.UTF8Encoding PS> echo 今日はいい天気です | & "C:\Program Files (x86)\MeCab\bin\mecab" 今日 名詞,普通名詞,副詞可能,*,*,*,キョウ,今日,今日,キョー,今日,キョー,和,*,*,*,*,*,*,体,キョウ,キョウ,キョウ,キョウ,1,C3,*,2509094191768064,9128 は 助詞,係助詞,*,*,*,*,ハ,は,は,ワ,は,ワ,和,*,*,*,*,*,*,係助,ハ,ハ,ハ,ハ,*,"動詞%F2@0,名詞%F1,形容詞%F2@-1",*,8059703733133824,29321 いい 形容詞,非自立可能,*,*,形容詞,連体形-一般,ヨイ,良い,いい,イー,いい,イー,和,*,*,*,*,*,*,相,イイ,イイ,イイ,イイ,1,C3,*,10716948459561665,38988 天気 名詞,普通名詞,一般,*,*,*,テンキ,天気,天気,テンキ,天気,テンキ,漢,*,*,*,*,*,*,体,テンキ,テンキ,テンキ,テンキ,1,C1,*,6972286733263360,25365 です 助動詞,*,*,*,助動詞-デス,終止形-一般,デス,です,です,デス,です,デス,和,*,*,*,*,*,*,助動,デス,デス,デス,デス,*,"形容詞%F2@-1,動詞%F2@0,名詞%F2@1",*,7051468750332587,25653 EOS
辞書が変わって出力される要素も増えました。列の名称は-Overboseオプションを付与することで出力されるようになりますが、その日本語名は先のUnidicのページに詳しい解説があります。
辞書は、mecabコマンドの -d オプションで指定する事もできます。たとえば、設定ファイルをUnidic変えた後で、IPADIC を利用したい場合は次のようにします。
SJIS環境のコマンドプロンプト
echo 今日はいい天気です | "C:\Program Files (x86)\MeCab\bin\mecab" -d "C:\Program Files (x86)\MeCab\dic\ipadic"
出力を変更
辞書を変えたら、出力形態が変わりましたが、この設定は辞書フォルダの中の dicrc ファイルで定義されています。
今回筆者がダウンロードした、Unidic の dicrcファイルの中身は次のようになっていました。
dicrc
dictionary-charset = utf8 config-charset = utf8 cost-factor = 700 max-grouping-size = 10 bos-feature = BOS/EOS,*,*,*,*,*,*,*,*,*,*,*,*,* eval-size = 12 unk-eval-size = 4 ;output-format-type=default node-format-unidic = %m\t%f[9]\t%f[6]\t%f[7]\t%F-[0,1,2,3]\t%f[4]\t%f[5]\t%f[13]\n unk-format-unidic = %m\t%m\t%m\t%m\tUNK\t%f[4]\t%f[5]\t\n ;unk-format-unidic = %m\t%m\t%m\t%m\t%F-[0,1,2,3]\t%f[4]\t%f[5]\t\n eos-format-unidic = EOS\n node-format-chamame = \t%m\t%f[9]\t%f[6]\t%f[7]\t%F-[0,1,2,3]\t%f[4]\t%f[5]\t%f[15]\t%f[11]\n unk-format-chamame = \t%m\t\t\t%m\t未知語\t\t\t\t\n ;unk-format-chamame = \t%m\t\t\t%m\t%F-[0,1,2,3]\t\t\t\t\n eos-format-chamame = bos-format-chamame = B
これは出力の設定の他に解析の設定も含みます、基本的に解析用のパラメーターは変更する必要はないと思いますが、各項目の意味をChatGPTの回答を参考にまとめると次のようになります。
- cost-factor
単語がいかに自然なつながりを保持しているかどうかをコストという概念で計算しているのですが(小さいほど自然)、この値が大きければ、単語間のコスト差が増大し小さければ縮小するそうです。
- max-grouping-size
未知語(辞書にない言葉)の最大文字数です。10ならば未知語は10文字以下で予測されます。
- bos-feature
単語の開始に関する特徴を記述するもののようです。
- eval-size
単語を推定する際に出す候補の数です。大きければその分負荷があがります。
- unk-eval-size
unk接頭は基本的にunknownの略のようで、先のeval-sizeの未知語バージョンです。
output-format-type から出力の設定となります。この値は、以降に作成するどのフォーマットをデフォルトにするかの設定となります。
- node-format-...
この最後の ...の部分が識別子となり、先のoutput-formt-typeに渡す値にもなります。ここでは「 unidic 」という出力設定のなかの node-format を定義しています。
この node-format が先の出力結果の出力指定となっています。
\tがタブ\nが改行等一般的なエスケープ文字の他、%を接頭とした特別な意味を持つ指定ができます。それらすべての設定はMeCab「出力フォーマット」のページに記載されていますが、主なものを紹介します。
- %f[インデックス]
単語に分割したあとの解析結果を保持した配列のどのインデックスの値を出すか指定します。
インデックスは,区切って複数指定できその際は、,によって分割されて出力されます。
- %FC[インデックス...]
%Fは複数のインデックスを指定する際に使います。%fとの相違点はCとしてをデリミタ(分割文字)を指定できるのと、空の要素がでてきた場合はそれ以降の出力をしないことです。
- %m
分割された単語を表示します。
特殊な文字以外はそのままの形で出力されます。
- %f[インデックス]
- unk-format-...
未知語に対するフォーマットを指定します。
Unidicでは未知語に対する出力項目数と、通常の項目数が違う為適切に設定しておかないと「 given index is out of range 」エラーが出力されます。
- eos-format-...
分割されたデータの表示の最後に出力する文字を指定します。EOS\n が一般的です。
- bos-format-...
データの最初に表示される文字を指定します。
...とした識別文字列は、設定ファイルの output-format-type に記述する他、コマンドラインオプションの -O に対して渡しても同じ結果が得られます。
コマンドプロンプト
echo 今日はいい天気です | "C:\Program Files (x86)\MeCab\bin\mecab" -d "C:\Program Files (x86)\MeCab\dic\ipadic" -O chasen2 今日 キョウ 今日 名詞-副詞可能 は ハ は 助詞-係助詞 いい イイ いい 形容詞-自立 形容詞・イイ 基本形 天気 テンキ 天気 名詞-一般 です デス です 助動詞 特殊・デス 基本形 EOS
output-format-type も -O オプションも指定されていない場合は、辞書独自の出力になるようです。
IPADICには読みだけを出力する yomi が設定されていたので、表題のように漢字のフリガナを取得する設定を Unidicで設定をしてみたいと思います。(IPADICを使う場合は -O yomi とするだけでフリガナが取得できます)
dicrc
... ; コメントアウトを解除して デフォルトのフォーマットを yomi に設定 output-format-type=yomi ; yomiフォーマットを設定 node-format-yomi = %f[6] ; 未定義の場合は読みが取得できないので?一字に代替 unk-format-yomi = ? ; 最後だけ改行 eos-format-yomi = \n
コマンドプロンプト
chcp 65001 echo 今日はいい天気です |"C:\Program Files (x86)\MeCab\bin\mecab" キョウハヨイテンキデス
Sudachi
せっかくなのでSudachiの方も少しだけふれておきます。
ページから本体と「system_core.dic」という表記がある辞書ファイルをダウンロードし本体のルートフォルダ(sudachi-0.5.3.jarと同じ階層)に辞書ファイルをコピーすれば準備完了です。
こちらははJavaのアプリケーションとなっていますので、Javaランタイムが必要です。バージョン17(Debian 17-ea+19-Debian-1)と、バージョン8(Windowsの Temurin build 1.8.0_302-b08)で試してみたところどちらでも問題なく動くようでした。
使い方はjava利用する都合でjava -jarとなる以外同じ要領です。ただしSudachiではデフォルトでは読みが出力されないので-aオプションをつける必要があります。
echo 今日は猫の日です | java -jar sudachi-0.5.3.jar -a 今日 名詞,普通名詞,副詞可能,*,*,* 今日 今日 キョウ 0 [981] は 助詞,係助詞,*,*,*,* は は ハ 0 [] 猫 名詞,普通名詞,一般,*,*,* 猫 猫 ネコ 0 [] の 助詞,格助詞,*,*,*,* の の ノ 0 [] 日 名詞,普通名詞,副詞可能,*,*,* 日 日 ヒ 0 [] です 助動詞,*,*,*,助動詞-デス,終止形-一般 です です デス 0 [] EOS
Sudachiでは提供されているコマンドラインインターフェースだけで読みだけ取得することはできなさそうです。