気象庁のサイトからクローラで天気予報を取得
筆者は以前より過去の天気を記録しておくために気象庁の天気予報ページにアクセスしてページを保存するスクリプトを組んでいたのですが、最近になってページがリニューアルして取得できなくなってしまいまいた。
以前はHTMLに記述されていたのでそのまま保存できたのですが、新しいページはJavaScriptで表示されるためページをそのまま保存しても肝心の天気の部分は保存されません。
そこで、Webで検索して出てきたQuiita:「Node.jsでウェブスクレイピングする色々な方法」を参考にさせていただき、Puppeteer(別名:Headless Chrome)を使って取得するようにしました。
このHeadless:ヘッドレスとは、コンソール内でブラウジングする事を指しています。
Node.js
PuppeteerはNode.js環境で実行します。もしNode.jsをインストールしていないようでしたらインストールしてください。それらの初期設定につきましては「Node.js環境の整備」の記事で紹介していますのでそちらを参考にしてください。
Puppeteerのインストールと基本的な使い方
ここではWindows10のPowerShellを使って、dドライブにプロジェクトを作成してそこにPuppeteerをインストールします。
PS> cd d:\
mkdir crawlers
npm init -y
...
npm install puppeteer
基本的な使い方は、先の公式サイトより引用させていただきました。この例ではbrowserインスタンスを作成して、そこからpageインスタンスを取得します。pageインスタンスのgotoメソッドに表示させたいページアドレスを渡すとページが表示されます。表示が終わったら、screenshotメソッドでブラウザに表示される内容を引数で渡したパスに画像として保存しています。
browserインスタンス作成時にlaunch({headless: false})と引数を渡してやると、Google Chromeに似たブラウザが起動されます。デバッグ時などはこの方が状態の遷移がわかりやすいと思います。
exsample.js
const puppeteer = require('puppeteer'); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('https://example.com'); await page.screenshot({ path: 'example.png' }); await browser.close(); })();
天気予報のページ
筆者がターゲットとしたページは各都市の「明後日までの詳細」と「7日先まで」が表示されるページです。

ターゲットのページを開いてGoogle ChromeのデベロッパーツールのElementsのタグから、取得に使えそうなタグやクラスを探ります。
それらをみつけられたら、コーディングに移ります。 pageのメソッドevaluateの引数に渡す関数内では、ヘッドレスブラウザが読み込んたDOMを操作できます。
方法はいろいろだと思いますが、大枠を取得するために、クラス名の「forecast-table」を指定して getElementsByClassNameを使うことにしました。
リンク先のMDNの説明にも書いてありますが、getElementsByClassNameが生きたHTMLCollectionを取得するというところが重要で、そうしないとJavaScriptで更新された部分は取得できません。
それともう一つ注意したいのは、evaluateの中ではconsole.log(...)としてもNode.js側には表示されません。そのコードはヘッドレスブラウザの中で実行されてしまうからです。同じ理由で必要な値は、一度戻り値としてNode.js側に戻す必要があります。
先のページをforecast-tableクラスで絞って選択すると次の8つが取得されました。2つ目と3つ目、6つ目と7つ目はそれぞれほぼ同じデータです。実際に表示されているのは3つ目と7つ目の方のようです。
- 明後日までの天気予報のヘッダ
- 明後日までの天気予報
- 明後日までの天気予報
- 選択都市の天気概況
- 7日先までの天気予報のヘッダ
- 7日先までの天気予報
- 7日先までの天気予報
- 所属する地方の天気概況
数件の都市で確認してだけなので、このようにならない場合もあるのかもしれませんがその際はご容赦ください。
あとはインデックスやタグ名を使って取得していきます。全体のコードは次のようになりました。
pageインスタンスのgotoに渡している、{ waitUntil: 'networkidle2'}の部分はスクリプトなどでページを表示するサイト用にwaitを入れるオプションです。
発表の時間によって「明後日」までの予報があったり、なかったりします。下のコード例は明後日の予報がある前提の記述となっています。getWeather.js
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.jma.go.jp/bosai/forecast/#area_type=class20s&area_code=0120200', {waitUntil: 'networkidle2'});
let result = await page.evaluate(() => {
//天気予報テーブルを取得
let tables = document.getElementsByClassName('forecast-table')
//戻り値初期化
let resultObj = {};
resultObj.day3=[];
for (let i = 0; i < 3; i++) {
resultObj.day3.push({日付:",天気:",降水確率:["","","",""],気温:["",""]});
}
//3番目のテーブル(明後日までの天気)
//2番目のtrのthに日付が入っている
let tr3s =tables[2].getElementsByTagName("tr");
let th3s =tr3s[1].getElementsByTagName("th");
resultObj.day3[0].日付=th3s[1].innerHTML;
resultObj.day3[1].日付=th3s[2].innerHTML;
resultObj.day3[2].日付=th3s[3].innerHTML;
//天気は3番目のtrにいるimgのタイトルから取得した方が簡潔な値が得られる
let imgs =tr3s[2].getElementsByTagName("img");
resultObj.day3[0].天気=imgs[0].title;
resultObj.day3[1].天気=imgs[1].title;
resultObj.day3[2].天気=imgs[2].title;
//降水確率は8番目のtrにあるtdに順番に入っている(明後日の分はなし)
let tds = tr3s[7].getElementsByTagName("td");
resultObj.day3[0].降水確率[0]=tds[0].innerHTML;
resultObj.day3[0].降水確率[1]=tds[1].innerHTML;
resultObj.day3[0].降水確率[2]=tds[2].innerHTML;
resultObj.day3[0].降水確率[3]=tds[3].innerHTML;
resultObj.day3[1].降水確率[0]=tds[4].innerHTML;
resultObj.day3[1].降水確率[1]=tds[5].innerHTML;
resultObj.day3[1].降水確率[2]=tds[6].innerHTML;
resultObj.day3[1].降水確率[3]=tds[7].innerHTML;
//気温はは11番目のtrにあるtdに順番に入っている(明後日の分はなし)
tds = tr3s[10].getElementsByTagName("td");
resultObj.day3[0].気温[0]=tds[0].innerHTML;
resultObj.day3[0].気温[1]=tds[1].innerHTML;
resultObj.day3[1].気温[0]=tds[2].innerHTML;
resultObj.day3[1].気温[1]=tds[3].innerHTML;
return resultObj;
});
console.log(result);
browser.close();
})();
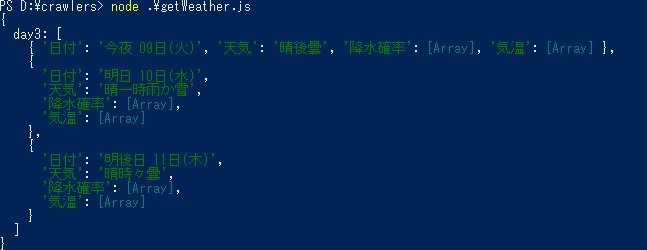
取得した結果をconsoleに出力したのがトップ画像です。
Debianでの実行
上記はWindows10環境で構築しましたが、これをDebian10(buster)環境に移植してみたら、いろいろと不具合が出現したので覚書として追記しておきます。
まず、Debian busterには執筆時点で、32bit環境が提供されていますが、Node.jsは32bit環境用の開発がバージョン10で終了しているようです。現行のLTS(Ver14)を使いたかったので筆者は32bit Debianでの稼働を諦めました。
64bit環境のDebianにNode.jsをインストールするには、GitHub:「nodesource/distributions」にあるように、root権限で次のようにします。
# curl -fsSL https://deb.nodesource.com/setup_lts.x | bash -
...
# apt-get install -y nodejs
...
次にプロジェクト用のディレクトリを作成・初期化し、puppeteerをインストールし、プログラムコードをコピーします。コードはユーザー権限で実行するので、ユーザー権限で作業をします。
$ cd get-weather
$ npm init -y
...
$ npm install puppeteer
...
$ cp xxxxxx ./getWeather.js
これで実行すると、まず次のようなエラーがでました。
これは公式のPuppeteer 3.0.0 refuses to launch on CI #5661に解決策が載っていました。
単にライブラリがないだけなので、インストールすれば解決します。
さらに今度は次のようなエラーに遭遇しました。
使えるサンドボックスがないので、カーネルをアップデートしてくださいという事です。カーネルをアップデートするのはちょっと……、と思っていたら、メッセ―ジは次のように続いていいました。
危険だけれども --no-sandboxオプションを使う方法があるそうです。この方法はQuiita:「CircleCI で puppeteer のテストを実行する」に指定の仕方が紹介されていました。ありがとうございました。参考になりました。コード中のpuppeteerのlaunchに次のように引数を渡すそうです。
これらの設定で、Debianでも実行することができました。