Cloud Visionの無料枠で文書画像を文字に変換(OCR)

レシートから家計簿を作るスマホアプリ等、フリーで画像を文字に変換(OCR)してくれるアプリがいろいろとあります。既成のアプリのいいところは手軽さなのですが、「ココ、こういう仕組みだったらいいのに」と思ったことありませんか。
そのような方向けに、自由にカスタマイズができるオリジナルのOCR機能を構築してみましょうというお話です。GoogleのCloud API であるCloud Visionは無料枠があるので、それを利用します。筆者の環境はWindows10&PHP7.4なので、それに従って書いていきますが、DebianやMac、JavaやNode.js等異なった環境でも同様のことはできると思います。
Google Cloud Vision
Cloud visionはテキスト変換だけでなく、顔の判別や、画像が暴力的かどうかを判断するセーフサーチ等、画像をAIで判別する総合的なAPIサービスとなっています。利用するためには課金登録が必要ですが、月に1000件までなら無料で利用できます。その後は1000件単位で、1.5ドル~(執筆時点)と気軽に利用できる価格となっています。
利用の仕方はまずGoogle Cloud Platform(GCP)から、プロジェクトを作成します。GCPの利用には登録が必要です。難しいものではありませんが、クレジットカード情報が必要です。リンク先ではその流れを紹介しています。 クレジットカードを登録したからといってすぐに料金が発生するものではありません。
「ナビゲーションメニュー」「APIとサービス」「APIライブラリ」と進み、「vision」をキーワードに検索してください。
「Cloud Vision API」という項目が表示されますので、選択して進み「有効にする」ボタンを押してください。

サービスアカウントの設定
Cloud Vision APIをローカルPCから操作できるようにするために、を設定します。「APIとサービス」タブより「認証情報」、「認証情報を作成」、「サービスアカウントの作成」と進めます。
「サービスアカウント名」に好きな名前を入れて「作成」を押します。次のページで「ロールの選択」を求められるので、「プロジェクト」「オーナー」にします。
ロールの「プロジェクト:オーナー」は、強い権限となっています。もし公開等をするならば適切な権限を指定するようにしてください。ここでは外に公開する予定はないので、プロジェクトのオーナーとしています。
「続行」を押して移動したページで、「キーの作成」「json形式」を選択します。するとキーがダウンロードされます。このキーが外に漏れると、第三者が自由にあなたのアカウントでサービスを利用できてしまいますので大切に保管してください。ダウンロードできたら完了を押します。
万が一、キーの漏洩が心配される事態になった場合は、サービスを削除します。サービスアカウントの項目からゴミ箱のアイコンをクリックします。必要に応じてキーを再作成してください。

ダウンロードしたファイルは後から利用します。
クライアントライブラリのインストール
APIをJavaやPHP、Node.jsといったどのプログラミング言語で使うかというのは人それぞれだと思いますが、ここではPHPを採用します。
公式:クライアント ライブラリの使用に従って進めますので、ほかの言語で利用したい場合はこちらも併せてご確認ください。
また、PHPで進める場合はそのライブラリを管理するソフトComposerも必要です。インストールしていなかったらインストールしてください。
コマンドプロンプトから、開発用のフォルダに移動します。ここではd:¥visionフォルダを新規作成して、そこに移動しています。
開発用のフォルダから、Composerを使って必要なライブラリをインストールします。
cd /d d:¥vision
composer require google/cloud-vision
サンプルの実行
次のコードが書かれた、ファイルを作成します。ここではd:¥vision¥test.phpとしました。
<?php
# Composerがvendorフォルダ内に必要なファイルをインストールしていますので、それをロードします。
require __DIR__ . '/vendor/autoload.php';
# ロードしたライブラリの中から、クラスをインポートしています。
use Google¥Cloud¥Vision¥V1¥ImageAnnotatorClient;
# インポートしたクラスのインスタンスを作成しています。
$imageAnnotator = new ImageAnnotatorClient();
# ここに画像ファイルのパスを入力してください。ファイルの区切りは/
$fileName = 'img/cherry.jpg';
# 画像ファイルを読み込んでいます。
$image = file_get_contents($fileName);
# 画像ファイルの識別を実行しています。
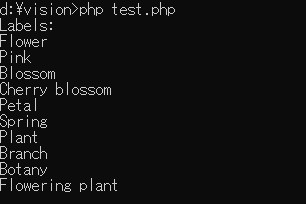
$response = $imageAnnotator->labelDetection($image);
$labels = $response->getLabelAnnotations();
if ($labels) {
echo("Labels:" . PHP_EOL);
foreach ($labels as $label) {
echo($label->getDescription() . PHP_EOL);
}
} else {
echo('No label found' . PHP_EOL);
}
?>テストにはこちらの画像を使ってみました。

thanks for photos(this and page top) to Hans in Pixabay
実行の前に、先にダウンロードしたキーを設定します。環境変数にキーファイルへのパスを設定することで、自動的に処理をしてくれるようになっています。環境変数の設定方法はコマンドラインで次のように入力します。ファイルのパスは¥を/に変換したうえで、自身の環境に合わせてください。
実行してみます。
エラーがでました。
まだどう?:cURL error 60: SSL certificate (GuzzleHttp v6)のページで解決策をみつけることができました。ありがとうございます。
解決方法は、こちらのページよりクライアント証明書をダウンロードし、保存先のファイルパスをphp.iniの「curl.cainfo」に記述するそうです。
再度、実行すると無事テスト画像を認識することができました。
テキストの認識
テストが終わったので、今度はテキストの認識をします。
テキスト読み込みをするには、公式の画像内の手書き文字を検出するに従い、コードを次のように変更します。
<?php
//名前空間の設定
namespace Google¥Cloud¥Samples¥Vision;
//外部ライブラリをロード
require __DIR__ . '/vendor/autoload.php';
//クラスのインポート
use Google¥Cloud¥Vision¥V1¥ImageAnnotatorClient;
//対象イメージ
$path = 'img/textjp.jpg';
//実行
detect_document_text($path);
//関数定義
function detect_document_text($path){
$imageAnnotator = new ImageAnnotatorClient();
$image = file_get_contents($path);
$response = $imageAnnotator->documentTextDetection($image);
$annotation = $response->getFullTextAnnotation();
# 読み出し
if ($annotation) {
foreach ($annotation->getPages() as $page) {
foreach ($page->getBlocks() as $block) {
$block_text = '';
foreach ($block->getParagraphs() as $paragraph) {
foreach ($paragraph->getWords() as $word) {
foreach ($word->getSymbols() as $symbol) {
$block_text .= $symbol->getText();
}
$block_text .= ' ';
}
$block_text .= "¥n";
}
printf('Block content: %s', $block_text);
printf('Block confidence: %f' . PHP_EOL,
$block->getConfidence());
# get bounds
$vertices = $block->getBoundingBox()->getVertices();
$bounds = [];
foreach ($vertices as $vertex) {
$bounds[] = sprintf('(%d,%d)', $vertex->getX(),
$vertex->getY());
}
print('Bounds: ' . join(', ', $bounds) . PHP_EOL);
print(PHP_EOL);
}
}
} else {
print('No text found' . PHP_EOL);
}
$imageAnnotator->close();
}
?>次のファイルを読み込んでみました。(青空文庫:オツベルと象 宮沢賢治より)

結果はこのようになりました。

かなりの精度のようにみてとれますが、この結果を出すまでには何度か挑戦しています。Windowsのメモ帳程度の行間だとうまく認識してくれませんでした。ワードのデフォルトの文字間隔ぐらいだと、精度が上がるようです。
片付け
もし使わなくなったら、何かの不具合で課金されてしまうことがないようにプロジェクトを削除しておきましょう。一時的に止めておきたいなら、APIの利用を停止したり、サービスキーを削除する方法があります。
プロジェクトを削除するには、次のようにプロジェクトのホーム画面から「プロジェクトの設定に移動」し「シャットダウン」を押します。その後はメッセージに従い、確認の為のプロジェクト名をいれて「シャットダウン」を押すと削除されます。

tessaractと比較
Googleがサービスとして公開しているVisionとは別に、Googleが開発に携わりオープンソースになっている「tessaract」というアプリがあります。元は同じだったという話も聞きますがどれぐらい違うのかためしてみたいと思います。
GAMMASOFT「Tesseract OCR をWindowsにインストールする方法」を参考に、インストーラーをダウンロード、「Additional script data」から「Japanese script」と「Japanese vertical script」を選択、「Additional language data」から「Japanese」と「Japanese(vertical)」を選択します。
このアプリはコマンドラインから次のようにして利用します。
lオプションで言語を指定します。インストールフォルダのxxx.traindataのxxx部分を指定します。なので縦書きの場合はjpn_vertとなります。複数の言語を指定したい場合はjpn+engといった形になります。
tesseract 5.0.0-alphaの実行結果
それではtesseractの実行結果です。
tesseract
オツウベルときたら大したもんだ。稲地いねこき吾械の六台も据すえつけて、のんのんの んのんのんのんと、大そろしない普をたててやっている。 十六人の百姓ひゃくしょうどもが、記をまるっきりまっ赤にして足で踏ふんで器械をま わし、小帆のように積まれた稲を片っぱしから緩こいて行く。医わらはどんどんうしろの 方へ接げられて、また新らしい山になる。そこらは、もみや某から発たったこまかな鹿 ちりで、変にばうっと鞭いろになり、まるで沙漠さばくのサむりのよう そのうすくぁい人仕事場を、オツウベルは、大きなお天明こはくのパイプをくわえ、吹殻ふき がらを某に落さないよう、眼めを細くして気をつっけながら、両手を背中に組みあわせて、 ぶらぶら往いったり来たりする。 小屋はずいぶん頑丈がんじょうで、学校ぐらいもあるのだが、何せ新式稲投器械が、六 台もそろってまわってるから、のんのんのんのんふるうのだ。中にはいるとそのため( すっかり腹が空すくほどだ。そしてじっさいオツベルは、そいつで上手に腹をへらし、ひ るめしどきには、六寸さらいのビブテキだの、閑店やうきんほどあるオムレツウの、ほくほ 人 をたべるのだ。 ※かく、そうして、のんのんのんのんやっていた。
見落としがあるかもしれませんが、下線部が間違えた箇所です。字下げは認識されませんでした。この表記だと改行部がわかりづらいかもしれませんが、画像の右端にあわせて改行が入ります。加えて字下げの前にひとつ改行が追加されるようです。※は文字欠けです。
Google Cloud Visionの実行結果
次にGoogle Cloud Visionです。
Google Cloud Vision
オッベルとしたら大したもんだ。 稲扱いねこき器械の六台も据すえつけて、 のんのんの んのんのんと、大そろしない音をたててやっている。 十六人の百姓ひゃくしょうどもが、顔をまるっきりまっ赤にして足で踏んで器械をま わし、小山のように積まれた稲を片っぱしから扱こいて行く。葉わらはどんどんうしろの 方へ投げられて、 また新しい山になる。 そこらは、 籾もみや葉やら発たったこまかな塵 ちりで、 変にぼうっと黄いろになり、 まるで砂漠のけむりのようだ。 そのうすくらい仕事場を、 オツベルは、 大きな琥珀 こはくのパイプをくわえ、 吹殻ふき がらを葉に落さないよう、 眼めを細くして気をつけながら、 両手を背中に組みあわせて、 ぶらぶら往いったり来たりする。 小屋はずいぶん頑丈がんじょうで、 学校ぐらいもあるのだが、 何せ新式稲扱器械が、 六 台もそろってまわってるから、のんのんのんのんふるうのだ。中にはいるとそのために、 すっかり腹が空 すくほどだ。 そしてじっさいオツベルは、 そいつで上手に腹をへらし、 ひ るめしどきには、 六寸ぐらいのビフテキだの、 雑巾ほどあるオムレツの、ほくほ くしたのをたべるのだ。 とにかくそうして、のんのんのんのんやっていた。
Google Cloud Visionの方は間違いがかなり少ないです。また画像の端では改行いれずに字下げの手前で改行を入れようとします。ところどころで余分な大小の余白ができますがその多くは画像の端の部分の空白や、句読点後の空白を余分にとっているものです。
tesseractの学習データの変更
期待しすぎていた部分もあるかもしれませんが、もう少しなんとかならないか試みました。tesseract-ocr/tessdata_bestに学習済データがあるので、jpn.traindataをダウンロードし、Tesseract-OCRのtessdataフォルダ内に上書き保存します。
結果はかわりましたが出来栄えは先の方がいいぐらいでした。